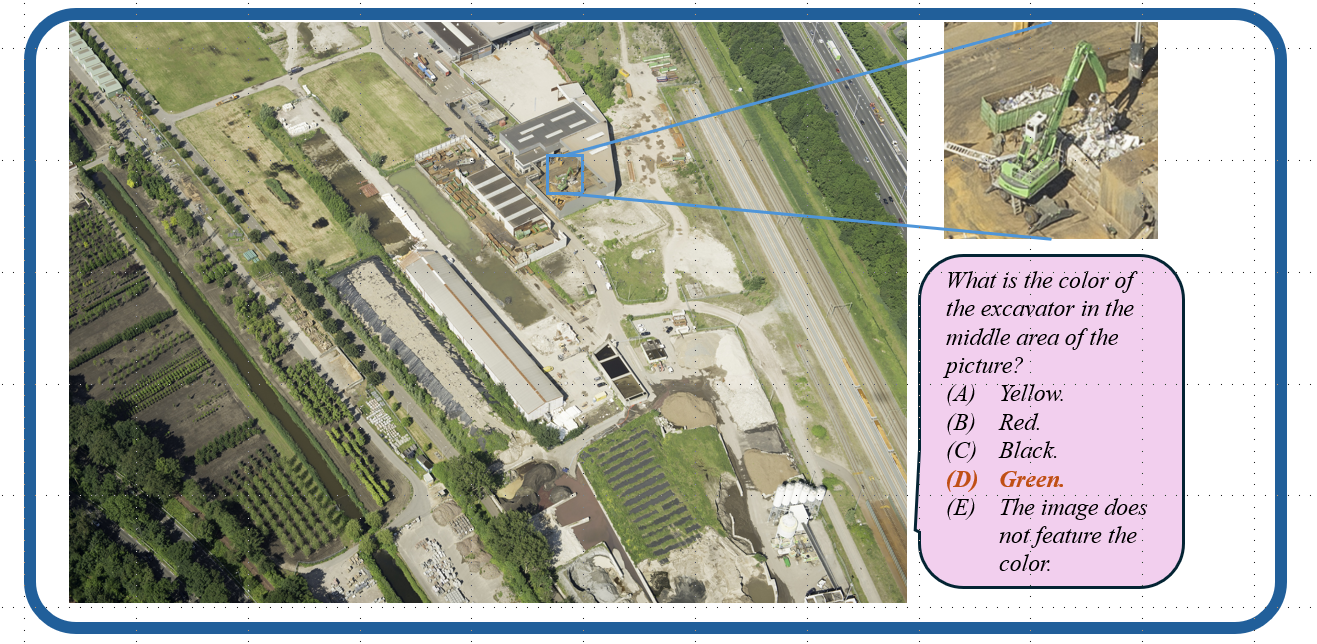
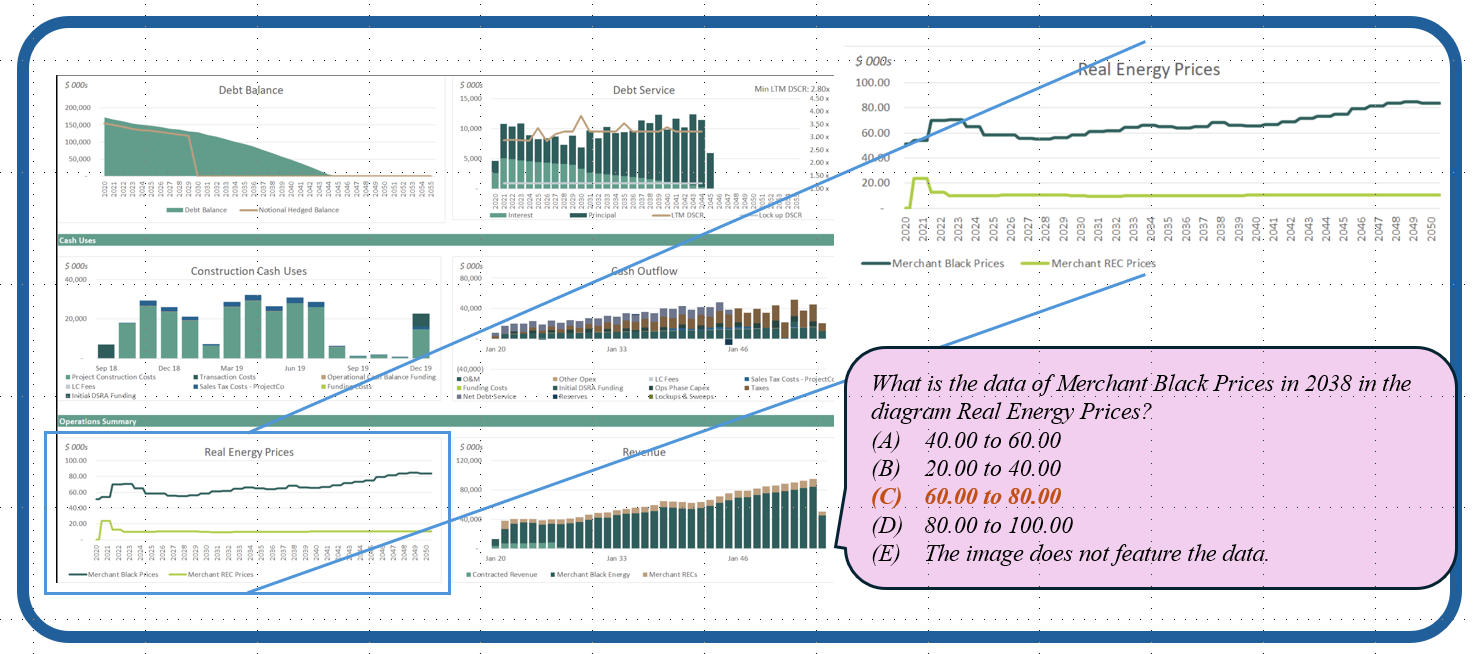
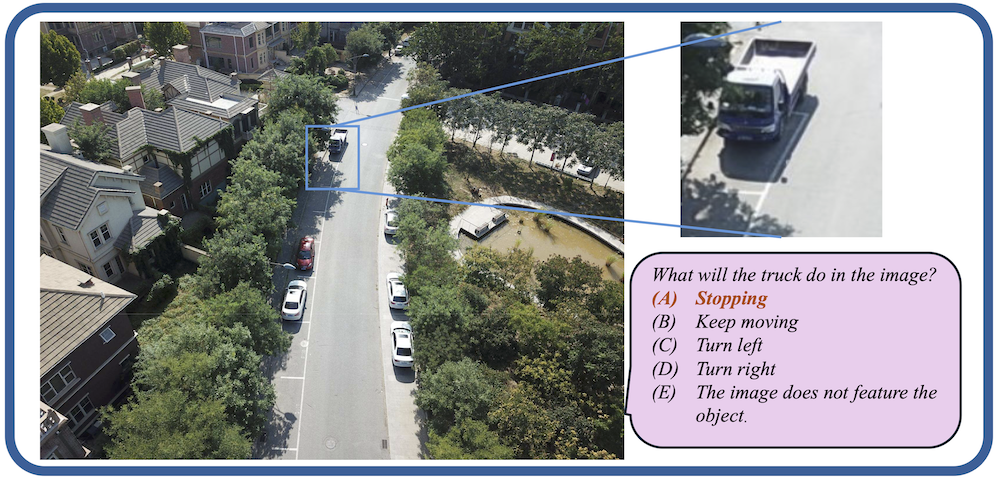
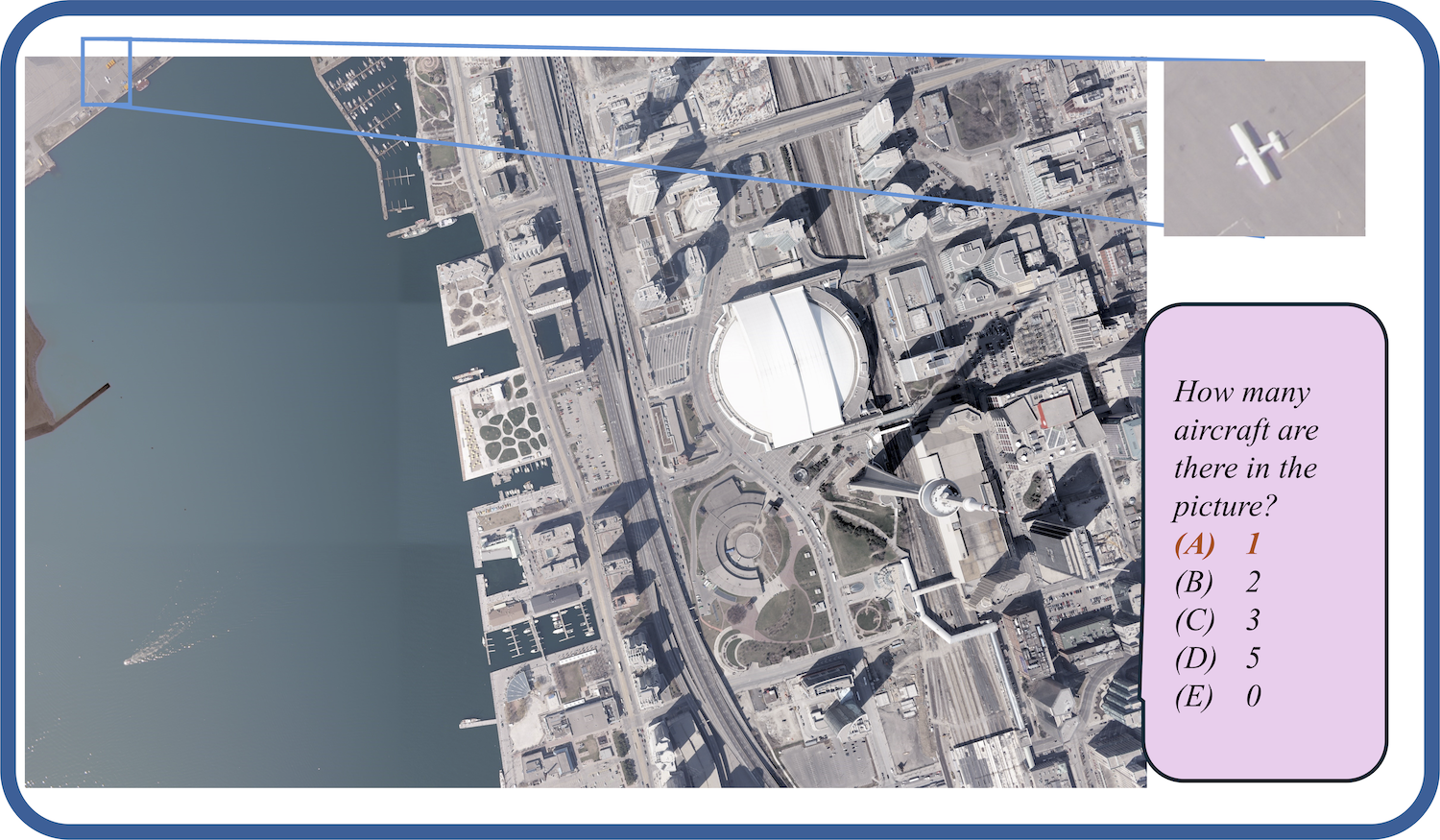
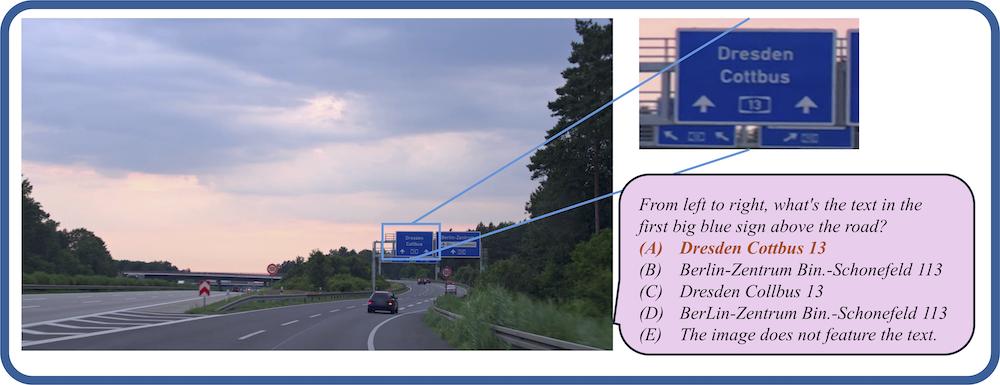
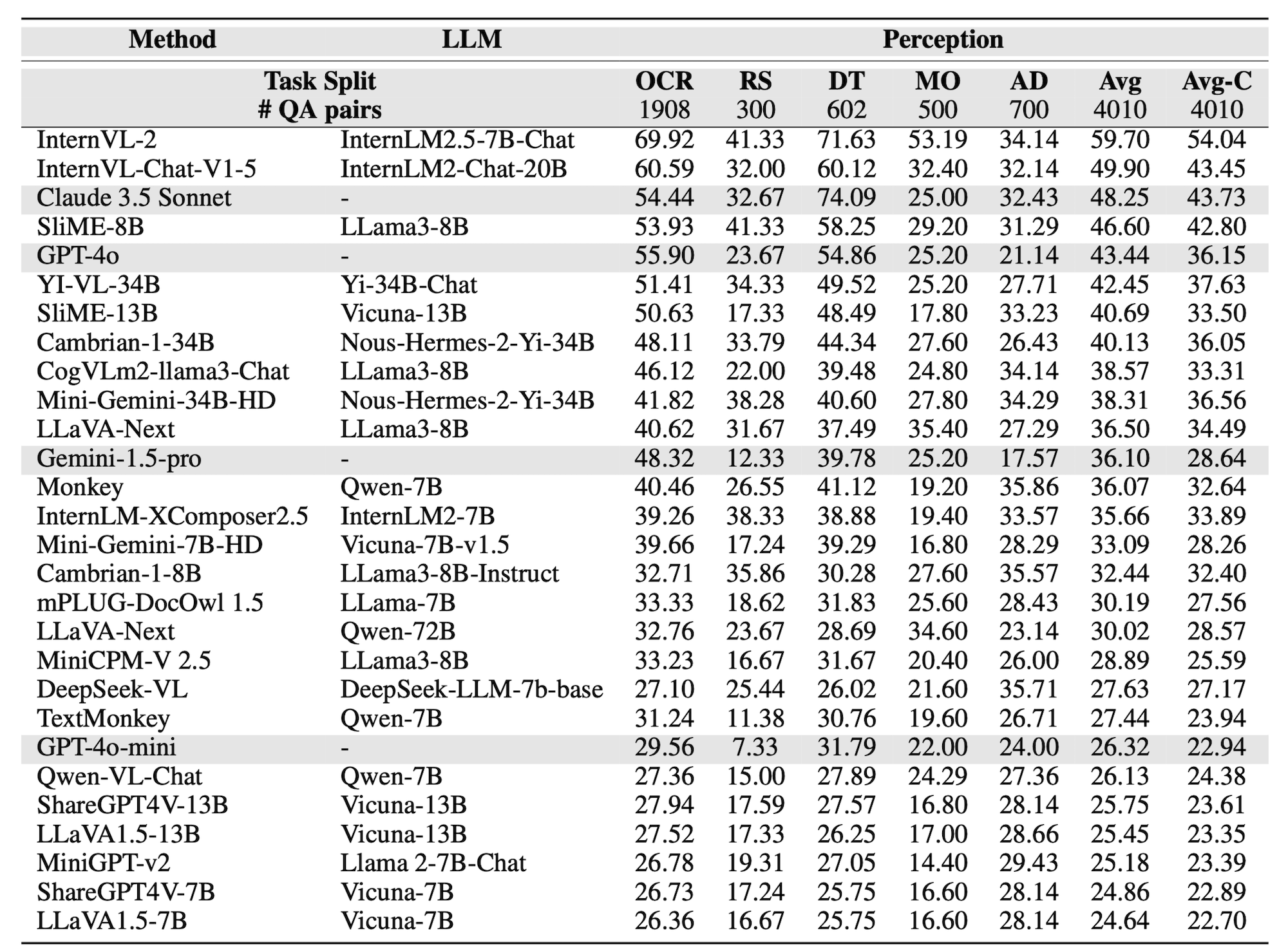
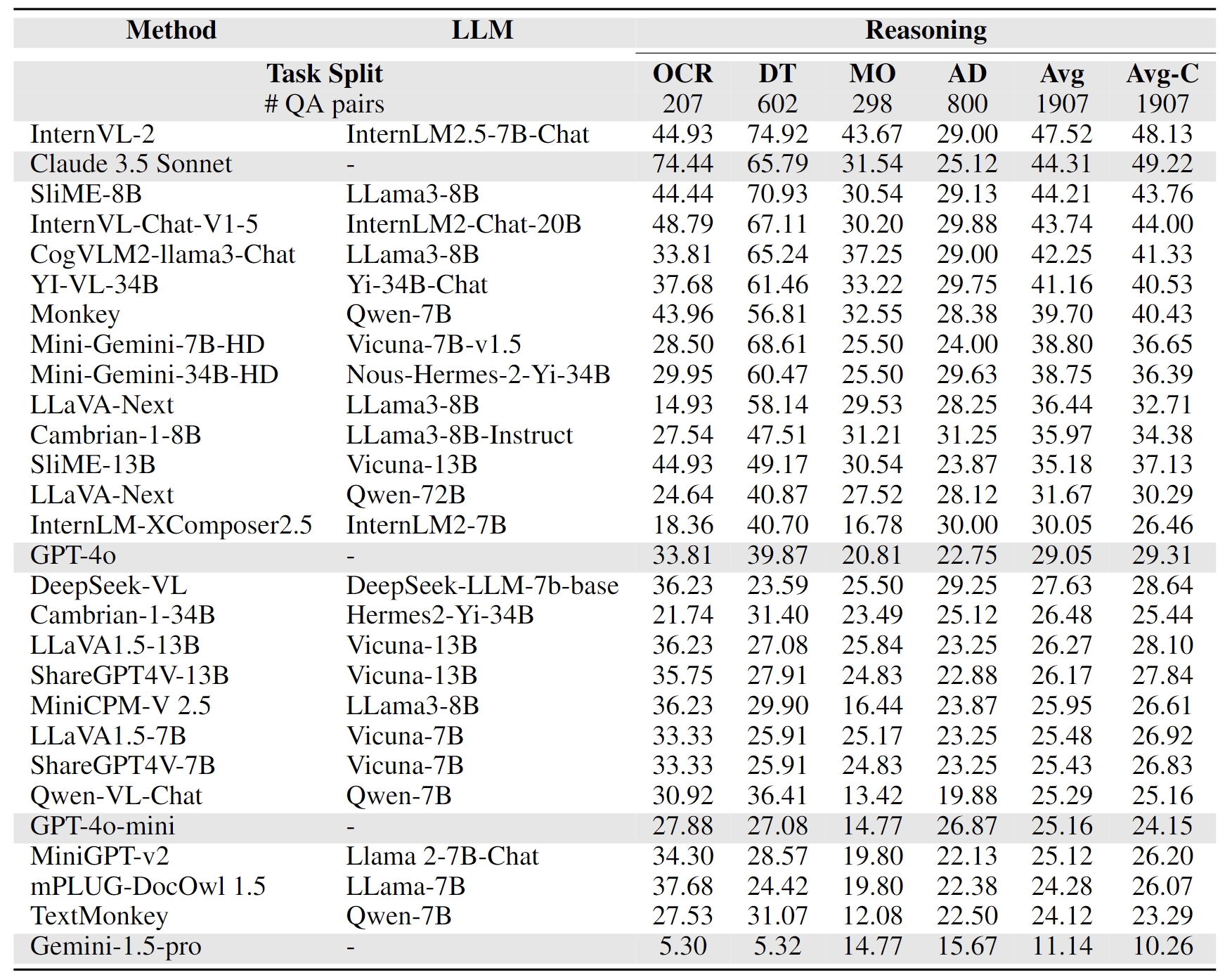
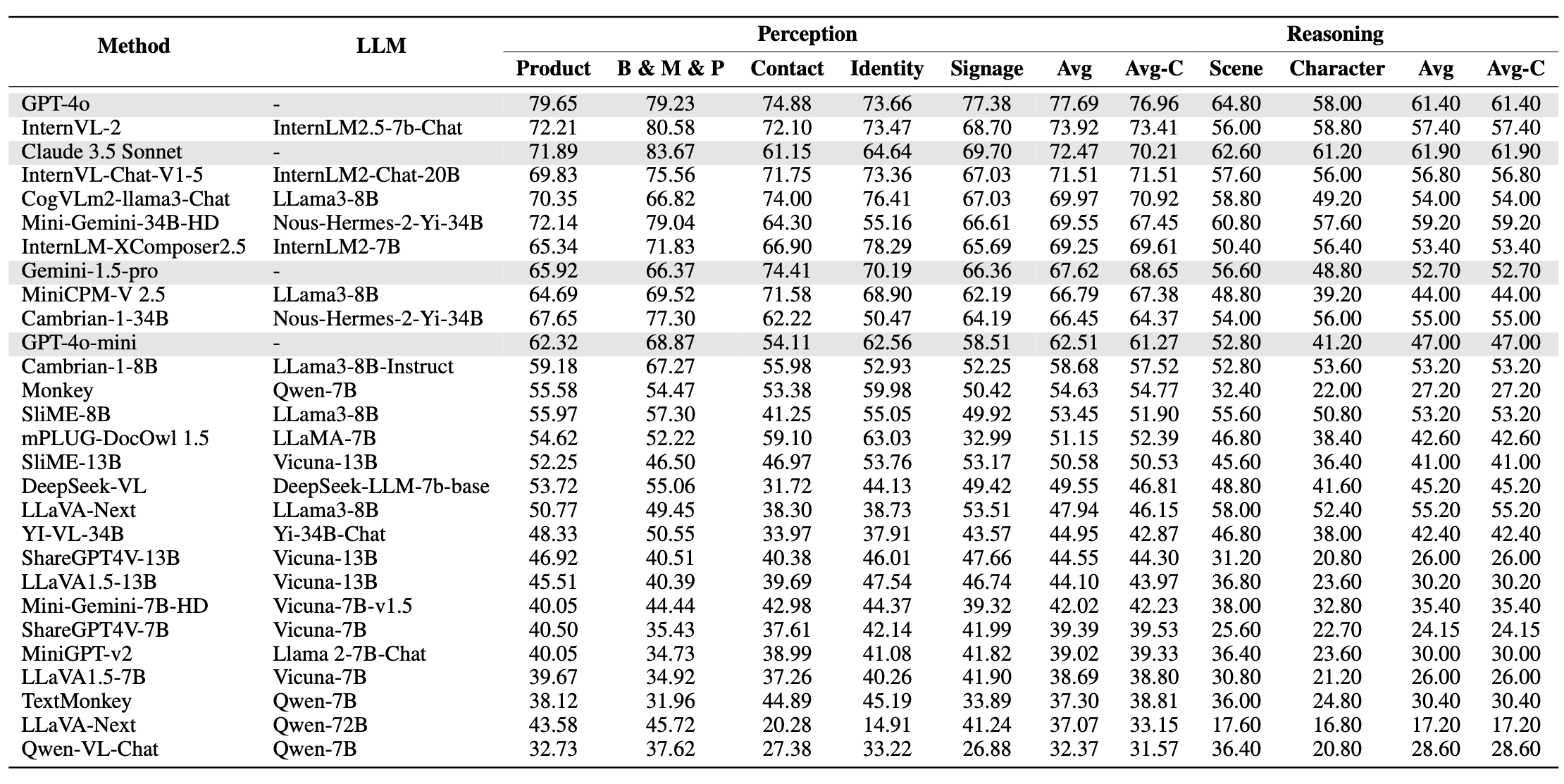
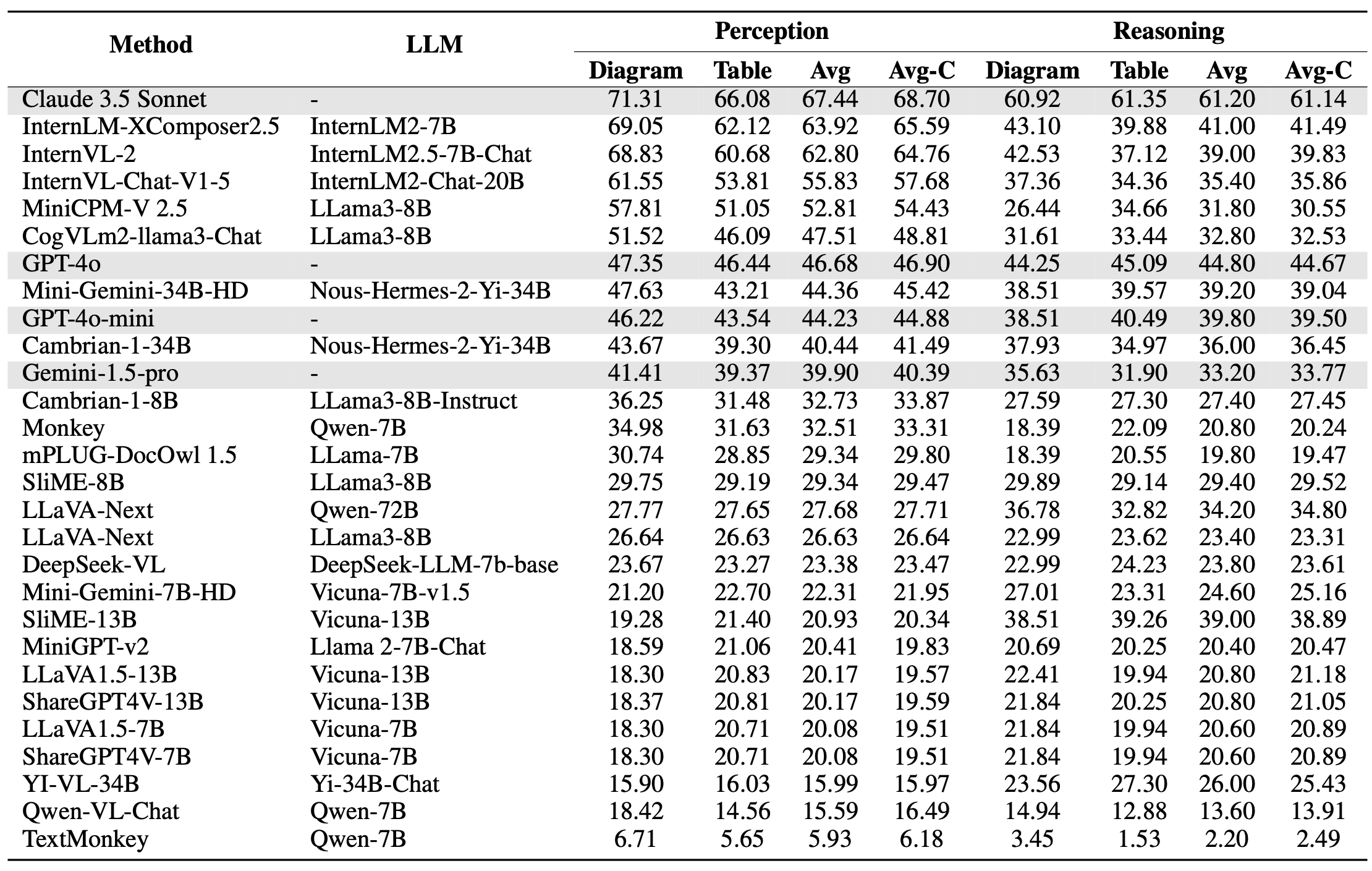
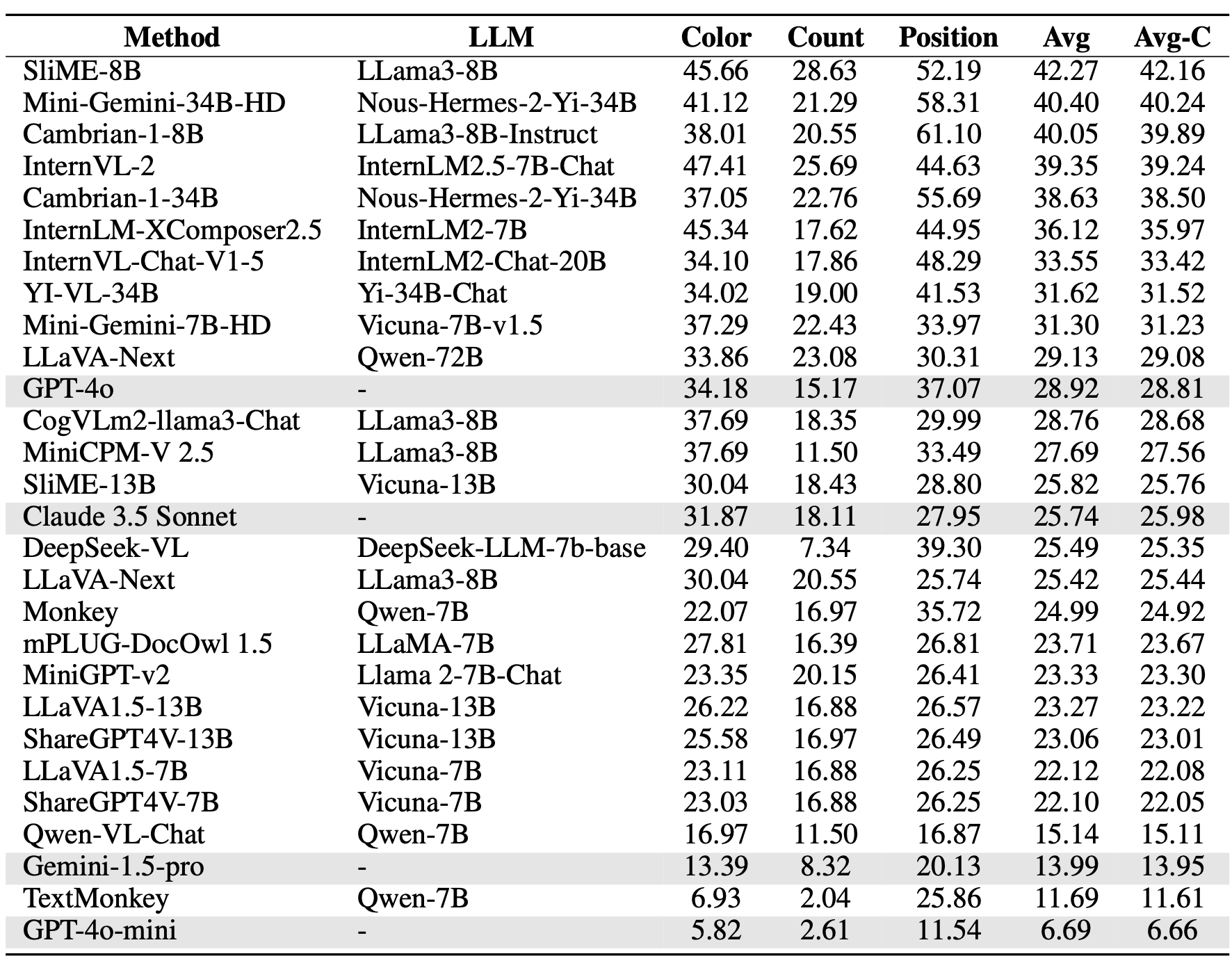
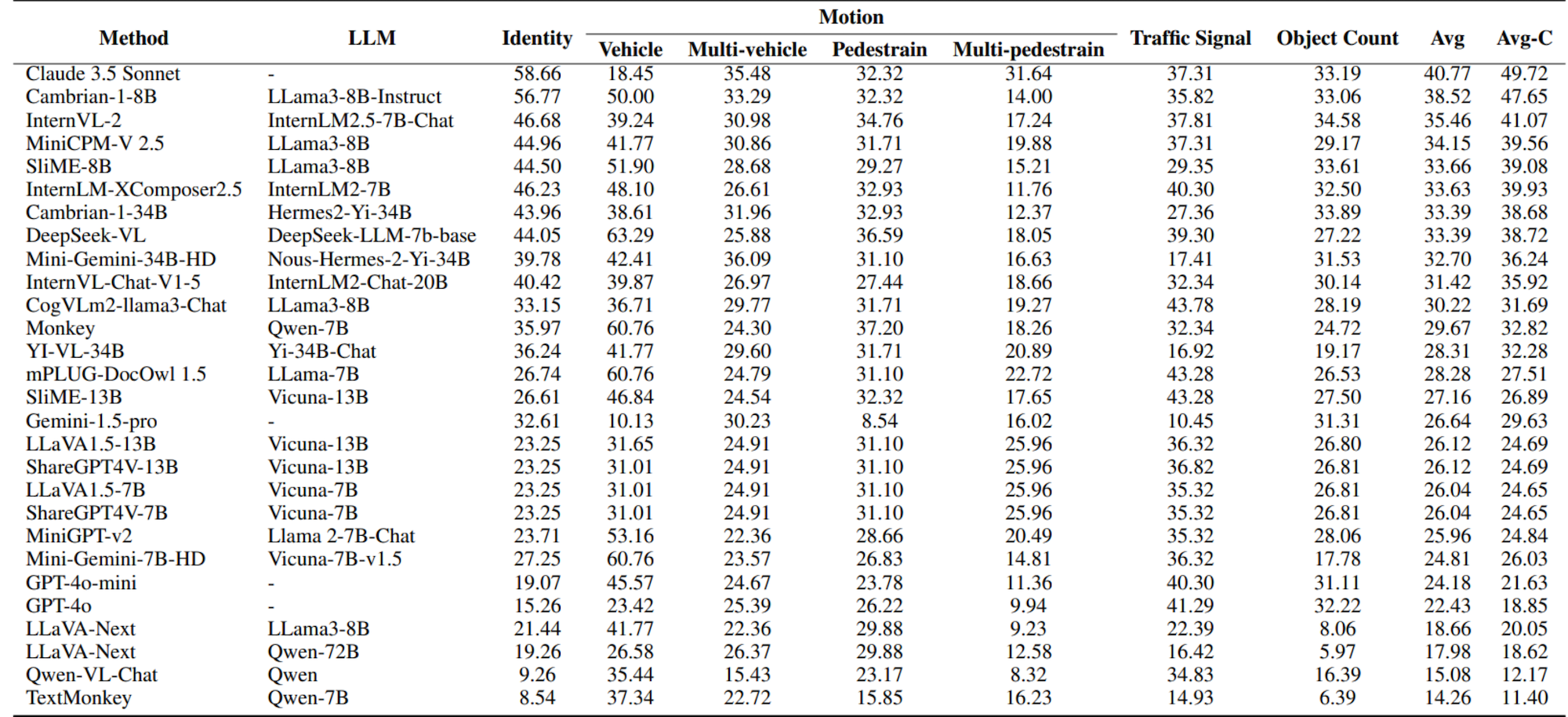
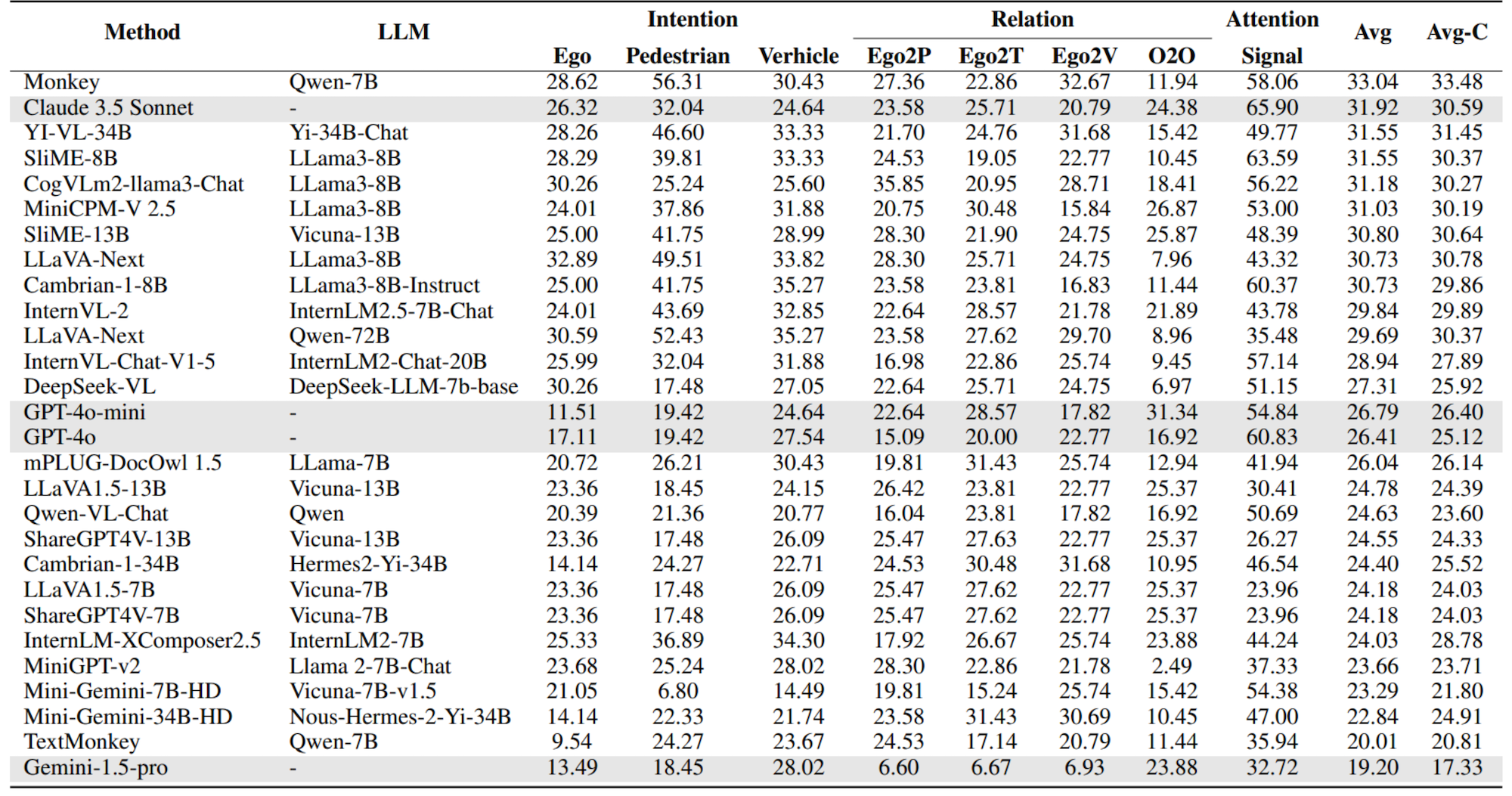
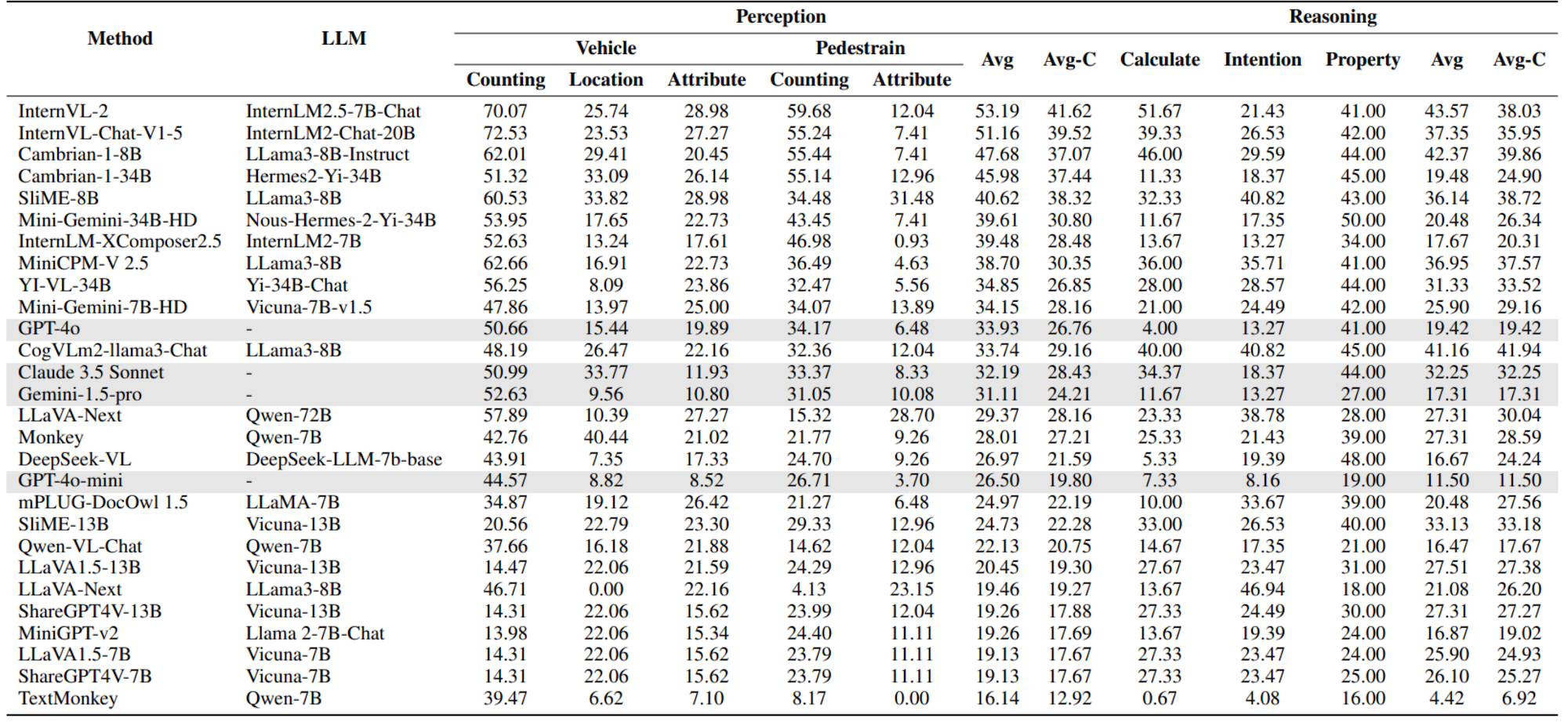
Models are ranked according to their average performance on perception and reasoning tasks, from highest to lowest. “OCR”, “RS”, “DT”, “MO” and “AD” each indicate a specific task domain: Optical Character Recognition in the Wild, Remote Sensing, Diagram and Table, Monitoring, and Autonomous Driving, respectively. “Avg” and “Avg-C” indicate the weighted average accuracy and the unweighted average accuracy across subtasks in each domain.
By default, this leaderboard is sorted by results with Overall. To view other sorted results, please click on the corresponding cell.
| # | Method | LLM | Date | Overall | Perception | Reasoning | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Task Split | Avg | OCR | RS | DT | MO | AD | Avg | Avg-C | OCR | DT | MO | AD | Avg | Avg-C | |||
| QA pairs | 23599 | 5740 | 3738 | 5433 | 2196 | 3660 | 20767 | 20767 | 500 | 500 | 498 | 1334 | 2832 | 2832 | |||
|
Awaker2.5-VL
Metabrain AGI |
9.8B | 2024-11-17 | 60.8 | 83.34 | 49.49 | 72.72 | 39.48 | 45.38 | 63.14 | 58.08 | 63.20 | 49.40 | 45.38 | 33.78 | 43.74 | 47.94 | |
|
InternVL2.5
Shanghai AI Lab |
8B | 2024-12-08 | 58.1 | 79.49 | 48.58 | 71.07 | 40.21 | 37.35 | 60.15 | 55.34 | 62.00 | 51.80 | 37.35 | 34.23 | 42.82 | 46.34 | |
|
LLaVA-OneVision
Bytedance & NTU S-Lab |
7B | 2024-09-29 | 57.4 | 78.69 | 53.53 | 60.70 | 40.26 | 45.77 | 59.59 | 55.81 | 61.80 | 40.00 | 40.76 | 34.08 | 41.17 | 44.16 | |
|
Qwen2.5-VL
Alibaba |
7B | 2025-02-13 | 57.3 | 84.60 | 39.22 | 77.97 | 38.52 | 28.83 | 59.99 | 53.83 | 62.80 | 59.80 | 20.88 | 26.04 | 37.54 | 42.61 | |
|
Qwen2-VL
Alibaba |
7B | 2024-09-03 | 56.5 | 81.38 | 44.81 | 70.18 | 37.30 | 34.62 | 58.96 | 53.66 | 63.40 | 48.60 | 33.13 | 31.47 | 40.39 | 44.15 | |
|
Xiaosuan-2.0-VL
OpenBayes |
- | 2024-09-30 | 55.7 | 80.75 | 44.66 | 68.01 | 37.07 | 31.94 | 57.64 | 52.48 | 63.40 | 49.40 | 35.74 | 31.62 | 41.06 | 45.04 | |
|
InternVL2
Shanghai AI Lab |
7B | 2024-08-26 | 53.5 | 73.92 | 39.35 | 62.80 | 53.19 | 35.46 | 55.82 | 52.94 | 57.40 | 39.00 | 43.57 | 29.84 | 38.74 | 42.45 | |
|
Claude 3.5 Sonnet
Anthropic |
- | 2024-08-26 | 51.6 | 72.47 | 25.74 | 67.44 | 32.19 | 40.77 | 52.90 | 47.72 | 61.90 | 61.20 | 41.79 | 31.92 | 44.12 | 49.20 | |
|
InternLM-XComposer2.5
Shanghai AI Lab |
7B | 2024-08-26 | 50.0 | 69.25 | 36.12 | 63.92 | 39.48 | 33.63 | 52.47 | 48.48 | 53.40 | 41.00 | 17.67 | 29.99 | 33.90 | 35.52 | |
|
InternVL-Chat-V1.5
Shanghai AI Lab |
20B | 2024-08-26 | 49.4 | 71.51 | 33.55 | 55.83 | 51.16 | 31.42 | 51.56 | 48.69 | 56.80 | 35.40 | 37.35 | 28.94 | 36.48 | 39.62 | |
|
Jiutian-FALCON
HITSZ |
8B | 2025-01-05 | 49.2 | 66.39 | 49.55 | 47.23 | 40.39 | 36.53 | 50.33 | 48.02 | 55.40 | 39.20 | 44.38 | 34.45 | 40.71 | 43.36 | |
|
VITA
Tencent Youtu Lab |
8*7B | 2024-09-12 | 47.5 | 70.60 | 39.40 | 42.60 | 37.50 | 38.20 | 48.40 | 45.66 | 62.20 | 31.80 | 43.20 | 35.40 | 40.90 | 43.15 | |
|
Mini-Gemini-34B-HD
CUHK |
34B | 2024-08-26 | 45.9 | 69.55 | 40.40 | 44.36 | 39.61 | 32.70 | 48.05 | 45.32 | 59.20 | 39.20 | 20.48 | 22.84 | 31.73 | 35.43 | |
|
MiniCPM-V 2.5
OpenBMB |
8B | 2024-08-26 | 45.6 | 66.79 | 27.69 | 52.81 | 38.70 | 34.15 | 47.37 | 44.03 | 44.00 | 31.80 | 36.95 | 31.03 | 34.50 | 35.95 | |
|
GPT-4o
OpenAI |
- | 2024-08-26 | 45.2 | 77.69 | 28.92 | 46.68 | 33.93 | 22.43 | 46.43 | 41.93 | 61.40 | 44.80 | 36.51 | 26.41 | 37.61 | 42.28 | |
|
CogVLM2-llama3-Chat
THU & Zhipu AI |
8B | 2024-08-26 | 44.6 | 69.97 | 28.76 | 47.51 | 33.74 | 30.22 | 45.85 | 42.04 | 54.00 | 32.80 | 41.16 | 31.18 | 37.25 | 39.62 | |
|
Cambrain-1-34B
NYU |
34B | 2024-08-26 | 44.1 | 66.45 | 38.63 | 40.44 | 45.98 | 33.61 | 46.68 | 45.02 | 55.00 | 36.00 | 19.48 | 16.07 | 27.06 | 31.64 | |
|
Cambrain-1-8B
NYU |
8B | 2024-08-26 | 42.7 | 58.68 | 40.05 | 32.73 | 47.68 | 38.52 | 43.82 | 43.53 | 53.20 | 27.40 | 42.37 | 30.73 | 36.16 | 38.43 | |
|
SliME-8B
CASIA |
8B | 2024-08-26 | 39.6 | 53.45 | 42.27 | 29.34 | 40.62 | 33.66 | 40.29 | 39.87 | 53.20 | 29.40 | 36.14 | 31.55 | 35.80 | 37.57 | |
|
Gemini-1.5-Pro
|
- | 2024-08-26 | 38.2 | 67.62 | 13.99 | 39.90 | 31.11 | 26.64 | 39.63 | 35.85 | 52.70 | 33.20 | 28.33 | 19.20 | 29.19 | 33.36 | |
|
GPT-4o-mini
OpenAI |
- | 2024-08-26 | 36.4 | 62.51 | 6.69 | 44.23 | 26.50 | 24.18 | 37.12 | 32.82 | 47.00 | 39.08 | 25.81 | 26.76 | 32.48 | 24.85 | |
|
Monkey
HUST |
7B | 2024-08-26 | 35.3 | 54.63 | 24.99 | 23.51 | 28.01 | 29.67 | 36.30 | 33.96 | 27.20 | 20.80 | 27.31 | 33.04 | 28.84 | 27.09 | |
|
mPLUG-DocOwl 1.5
Alibaba |
7B | 2024-08-26 | 32.7 | 51.15 | 23.71 | 29.34 | 24.97 | 28.28 | 33.71 | 31.49 | 42.60 | 19.80 | 20.48 | 26.04 | 26.88 | 27.23 | |
|
DeepSeek-VL
DeepSeek-AI |
7B | 2024-08-26 | 32.4 | 49.55 | 25.49 | 23.38 | 26.97 | 33.39 | 33.14 | 31.76 | 45.20 | 23.80 | 16.67 | 27.31 | 27.98 | 28.25 | |
|
SliME-13B
CASIA |
13B | 2024-08-26 | 31.7 | 50.58 | 25.82 | 20.93 | 24.73 | 27.16 | 31.50 | 29.84 | 41.00 | 39.00 | 33.13 | 30.80 | 34.46 | 35.98 | |
|
YI-VL-34B
01.AI |
34B | 2024-08-26 | 31.0 | 44.95 | 31.62 | 15.99 | 34.85 | 28.31 | 30.97 | 31.14 | 42.40 | 26.00 | 31.33 | 31.55 | 32.45 | 32.82 | |
|
Mini-Gemini-7B-HD
CUHK |
7B | 2024-08-26 | 30.3 | 42.02 | 31.30 | 22.31 | 34.15 | 24.81 | 31.07 | 30.92 | 35.40 | 24.60 | 25.90 | 23.29 | 26.12 | 27.30 | |
|
LLaVA-NeXT-LLama3-8B
Bytedance & NTU S-Lab |
8B | 2024-08-26 | 30.2 | 47.94 | 25.42 | 26.63 | 19.46 | 18.66 | 30.14 | 27.62 | 55.20 | 23.40 | 21.08 | 30.73 | 32.06 | 32.60 | |
|
LLaVA-NeXT-Qwen-72B
Bytedance & NTU S-Lab |
72B | 2024-08-26 | 28.7 | 37.07 | 29.13 | 27.68 | 29.37 | 17.98 | 29.01 | 28.25 | 17.20 | 34.20 | 27.31 | 29.69 | 27.86 | 27.10 | |
|
LLaVA1.5-13B
UW-Madison |
13B | 2024-08-26 | 28.0 | 44.10 | 23.27 | 20.17 | 20.45 | 26.12 | 28.42 | 26.82 | 30.20 | 20.80 | 27.51 | 24.78 | 25.51 | 25.82 | |
|
ShareGPT4V-13B
USTC & Shanghai AI Lab |
13B | 2024-08-26 | 27.8 | 44.55 | 23.06 | 20.17 | 19.26 | 26.12 | 28.38 | 26.63 | 26.00 | 20.80 | 27.31 | 24.55 | 24.63 | 24.67 | |
|
MiniGPT-v2
KAUST & Meta AI |
7B | 2024-08-26 | 26.4 | 39.02 | 23.33 | 20.41 | 19.26 | 25.96 | 26.94 | 25.60 | 30.00 | 20.40 | 16.87 | 23.66 | 23.01 | 22.73 | |
|
ShareGPT4V-7B
USTC & Shanghai AI Lab |
7B | 2024-08-26 | 26.3 | 39.39 | 22.10 | 20.08 | 19.13 | 26.04 | 26.73 | 22.35 | 24.15 | 20.60 | 26.10 | 24.18 | 23.88 | 23.76 | |
|
LLaVA1.5-7B
UW-Madison |
7B | 2024-08-26 | 26.1 | 38.69 | 22.12 | 20.08 | 19.13 | 16.04 | 26.54 | 25.21 | 26.00 | 20.60 | 25.90 | 24.18 | 24.17 | 24.17 | |
|
Qwen-VL-Chat
Alibaba |
7B | 2024-08-26 | 21.1 | 32.37 | 15.14 | 15.59 | 22.13 | 15.08 | 20.75 | 20.06 | 28.60 | 13.60 | 16.47 | 24.63 | 21.95 | 20.83 | |
|
TextMonkey
HUST |
7B | 2024-08-26 | 17.8 | 37.30 | 11.69 | 5.93 | 16.14 | 14.26 | 18.18 | 17.06 | 30.40 | 2.20 | 4.42 | 20.01 | 15.96 | 14.26 | |